- 安易免费财务软件交流论坛 (http://bbs.anyicw.com/bbs/index.asp)
-- 电脑知识交流 (http://bbs.anyicw.com/bbs/list.asp?boardid=11)
---- SQL Server2008存储结构之堆表、行溢出(四) (http://bbs.anyicw.com/bbs/dispbbs.asp?boardid=11&id=32404)
-- 发布时间:2011/1/13 8:49:28
-- SQL Server2008存储结构之堆表、行溢出(四)
下面让我们将该记录的describle字段更新为非空值后,再看看该记录存储结构相应的变化。
再次使用dbcc page(testdb,1,224,1)命令
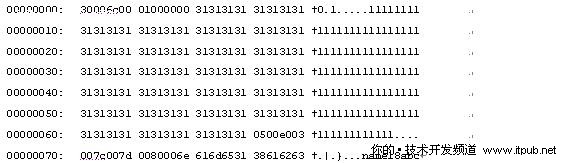
我们不难发现状态A,状态B,定长长度、定长内容和字段总数是没有发生任何变化的。
NULL位图部分变成了e0即11100000,表示describle字段即第五个字段不为空了
第一个和第二个变长列数据终止位置分别加了2个长度,这是因为当第三个变长列变更为非空后,自动添加了2个字节的第三个字段的维护字段
第一个变长列数据终止位置从7a00变更为7c00
第二个变长列数据终止位置从7b00变更为7d00
新增加的第三个变长列终止位置为8000
同时在第一、二列变长列的数据后面新增加了616263,即字符串”abc”
还有一个最显著的区别就是该记录的偏移位置显然转到了尾部,即5F1E的位置;但很奇怪的是该记录原来的位置上还保留着原值,并没有删除掉。也就是说对于该记录而言,应该是先删除,然后又添加了一条新纪录,只是把指针指向了新的偏移地址而已。
最后观察一下记录是如何删除的
当我们对比一下删除前后两条记录的信息,发现基本上原来的位置上数据没有发生任何变化,只是原来的slot1和slot2已经不存在了。即SQL Server认为该数据已经不存在了。

行溢出页面
USE TESTDBCREATE TABLE testOverFlow
(
ID INT IDENTITY(1,1),
NAME1 VARCHAR(5000),
NAME2 VARCHAR(5000)
)
INSERT INTO testOverFlow (NAME1,NAME2)
SELECT REPLICATE(\'A\',5000),REPLICATE(\'AB\',2500)
UNION
SELECT REPLICATE(\'B\',5000),REPLICATE(\'BA\',2500)
SELECT * FROM testOverFlow
SELECT type_desc
total_pages,used_pages,data_pages,
testdb.dbo.f_get_page(first_page) first_page_address,
testdb.dbo.f_get_page(root_page) root_address,
testdb.dbo.f_get_page(first_iam_page) IAM_address
FROM sys.system_internals_allocation_units
WHERE container_id IN (SELECT partition_id FROM sys.partitions
WHERE object_id in (SELECT object_id FROM sys.objects
WHERE name IN (\'testoverflow\')))
DBCC TRACEON(3604)
DBCC PAGE(testdb,1,54242,2) --行内数据
DBCC PAGE(testdb,1,52343,2) --行迁移数据
--同时我们也可以通过dbcc ind获取所有数据页面地址,然后进行页面信息显示
TRUNCATE TABLE tablepage;
INSERT INTO tablepage EXEC (\'DBCC IND(testdb,testOverFlow,1)\');
SELECT
PagePID,IAMPID,ObjectID,IndexID,Pagetype,IndexLevel,
NextPagePID,PrevPagePID
FROM tablepage
在NAME2字段之前和普通的行记录信息是一致的,我们只从NAME2字段开始就可以了。NAME2字段在NAME1字段之后,保存了以下内容,即改列的溢出列类型、节点类型、数据库更新次数、字段长度、指向OVERFLOW页的指针。
| 0200 | 0000 | 0100 | 00009d75 | 0000 | 8813 0000 | 77cc0000 0100 0000000 |
| 溢出列类型 | 节点类型 | Lob数据更新次数 | ID | 未知 | 字段长度 | 行溢出指针 |
| RowOVerFlow | 0 | 1 | 1973223424 | 5000 | 1:52343:0 |
让我们再来看一下第52343页看一下行溢出页的数据情况,该页面首先是一个LOB类型的页面,然后主要包括该字段的长度、关联ID,和数据行;很显然行 内数据和溢出行数据的关联是通过一个行溢出指针和ID进行的;因此对某个数据查询而言,首先要找到该记录的信息,同时如果发生行溢出,还有根据该列的行溢 出指针和关联ID,才能找到整条记录。
| 1个字节 | 1个字节 | 2个字节 | 8个字节 | 4个字节 | 2个字节 |
| 08 | 00 | 9613 | 00009d75 | 00000000 | 0300 |
| 状态A | 状态B | 字段长度 | ID | unkown | 类型 |
| 即包含行溢出 | 5014(同变长字段) | 1973223424 | 未知 | lob数据行 |
LOB页面
从SQL Server 2005版本以后中,新增加了大值数据类型varchar(max)、nvarchar(max)、varbinary(max)。大值数据类型最多可以存储2^30-1个字节的数据。
从行为上来讲这几个数据类型和之前的数据类型 varchar、nvarchar 和 varbinary 相同。
按照微软的说法是用这个数据类型来代替之前的text、ntext 和 image 数据类型,它们之间的对应关系为:
varchar(max)-------text;
nvarchar(max)-----ntext;
varbinary(max)----image
对大值数据类型的操作更类似于之前的varchar和varbinary之后,因此用法上也比之前的text和image比灵活和便宜。同时触发器也可以直接引用大值数据类型;而之前的text和image是不行的。
因此varchar(max)与varchar(n)和text有着千丝万缕的联系。对于varbinary(max)也一样。
因为之前我们已经观察过varchar(n)的行为,那么让我们看看这个新的varchar(max)与varchar(n)、text到底有什么不同。
CREATE TABLE testVARCHARMAX
(
ID INT IDENTITY(1,1),
name VARCHAR(20),
remark VARCHAR(MAX)
)
CREATE TABLE testTEXT
(
ID INT IDENTITY(1,1),
name VARCHAR(20),
remark TEXT
)
INSERT INTO testVARCHARMAX (name,remark)
SELECT REPLICATE(\'A\',20),REPLICATE(\'AB\',2500)
UNION
SELECT REPLICATE(\'B\',20),REPLICATE(\'BA\',2500)
INSERT INTO testTEXT (name,remark)
SELECT REPLICATE(\'A\',20),REPLICATE(\'AB\',2500)
UNION
SELECT REPLICATE(\'B\',20),REPLICATE(\'BA\',2500)
SELECT c.name,a.type_desc
total_pages,used_pages,data_pages,
testdb.dbo.f_get_page(first_page) first_page_address,
testdb.dbo.f_get_page(root_page) root_address,
testdb.dbo.f_get_page(first_iam_page) IAM_address
FROM sys.system_internals_allocation_units a,sys.partitions b,sys.objects c
WHERE a.container_id=b.partition_id and b.object_id=c.object_id
AND c.name in (\'testVARCHARMAX\',\'testTEXT\')
运行结果如下:

我们很容易发现两者的共同之处,就是两个表都包括LOB_DATA数据类型的分配单元,但是testVARCHARMAX表的LOB_DATA并没有分 配页面,而testTEXT表却分配了3个页面;同时testVARCHARMAX表比testTEXT表多了一个数据页面,这是怎么回事呢?
让我们首先看看testVARCHARMAX表的第217个数据页面

让我们通过Internals Viewer插件看一下对该记录的解读
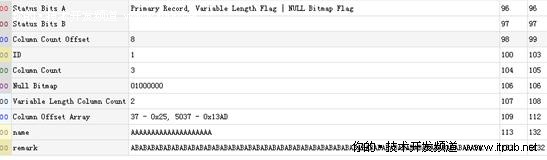
与之前的堆表的介绍相比,基本上我们可以看到与varchar(n)的存储结构式完全一致的,在此就不多做叙述了。
那么testTEXT表为什么会使用到LOB类型页面呢?我们使用dbcc page命令查看一下。
运行dbcc page(testDB,1,222),我们从第96个字节开始阅读。
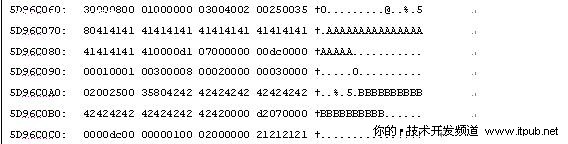
从这个角度,我们看到222页面类似于前面所讲到的行溢出页面,即在222页面保留了一个指向行溢出页面的指针
运行dbcc page(testDB,1,220,2),我们从第96个字节开始阅读。
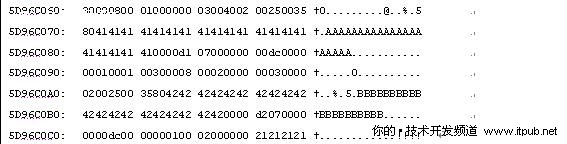
实际上我们从name字段内容之后阅读就可以了,即0000d1 07000000 00dc0000 00010001 00

是不是有点像缩略版的行溢出信息?
既然有行溢出指针,必然有行溢出页面,那我们再看看行溢出页面的数据页,即220页面。实际上我们用dbcc page(testdb,1,220,3)阅读该页的信息更简明一些。
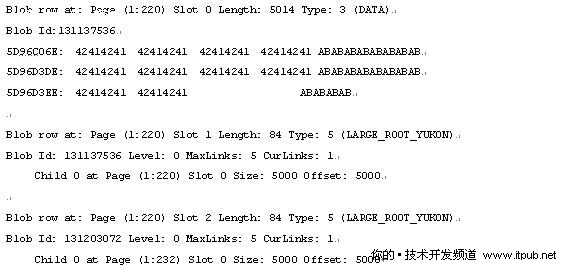
很明显slot 0记录了第一条记录remark字段的长度、数据类型和内容。
Slot 1,slot 2分别为两个指针,记录了remark字段的偏移地址和相应的文件号、页面和槽号
这个与之前的行溢出页面是有所不同的。